
Every great app idea starts small with a few users and a big dream. Maybe it began as a weekend project that took off faster than expected. Or perhaps it began as a scrappy startup MVP that suddenly found itself serving hundreds (then thousands) of requests per minute.
That’s when you hit the point every developer eventually faces: “Okay, this works …. But how do we scale it?”
Scaling in this context is about increasing the ability of the underlying system to handle ever-increasing user demands. It’s about understanding where your bottlenecks are, and evolving your architecture step-by-step to meet real-world growth. It’s about striking that delicate balance between having sufficient capacity to meet demand and not over-paying for resources you don’t yet need.
So let’s take a guided tour through the typical scaling journey — from that first deployment to a globally distributed system — and explore what happens at each stage.
Phase 1: The Humble Beginning
In the beginning, your infrastructure requirements may be very minimal. You may be able to host very small projects entirely on a shared web hosting plan, like you would use for a WordPress blog or small e-Commerce site.
When you first launch, simple is best. In this scenario, typically you will have:
Typical start-up set-up

A Web Server
A single web server running your frontend (what users interact with, like a website or web app) and backend (where your business logic lives).
A Database
A database on the same machine.
Local Storage
Local storage for user uploads (i.e. if a user uploads an image or a document, it is stored on the same computer that hosts your application).
Recurring Jobs
Maybe a scheduled job or two for background work (e.g. sending subscription reminder emails every morning at 2am).
But as your user base grows...
…this all-in-one setup starts to feel the strain. Effectively, you can become a victim of your own success.
You start to experience:
Traffic jams
One user uploads a video, or interacts with the app in a completely normal way, but everyone else experiences slow page loads.
Resource Hogs
Background jobs and database queries compete for CPU and memory.
Service Interruptions
Backups or scheduled cron jobs cause unpredictable, temporary downtime and outages.
Communal Storage Conflicts
If you do not have a dedicated server, then performance of your app can be impacted by high traffic or heavy processing by other users sharing the same hardware.
No Failsafe
The single server is also a single point of failure. If anything goes wrong with the server, your entire app is down, and you may not even be able to access the data to move it to a new machine.
Growing pains are signs of success.
When you start to outgrow your first technology solution, it’s a sign you’re taking off. So once you have those users and some evidence that your app will in fact continue to grow, these are the signals that it is time to evolve.
You can employ vertical scaling....
The simplest way to respond to growing user demands is to scale vertically by upgrading your server with more memory, disk space, or CPU capacity. If your family is growing, you might (for example) replace your two-door mini-coupe with a van. It’s instant gratification: your app breathes again.
But... this only works up to a point.
Bigger machines get exponentially more expensive, and one crash still takes your entire app down. Still, if you need to scale in a hurry, this will work to a point.
Phase 2: To Cloud or not to Cloud, that is the question!
Self-hosting
Pros
Excellent for compute-heavy or storage-heavy workloads.
Lower predictable monthly cost compared with cloud solutions.
Cons
This can be costly and time-consuming. It may take days or weeks to acquire and install new hardware.
Less geographic reach and redundancy. If a machine physically breaks, it is up to you to have it repaired before you can continue working.
Harder to automate provisioning or recovery.
Cloud Solutions
So-called “cloud computing” platforms such as Microsoft Azure, Amazon Web Services (AWS), Google Cloud (GCP), Digital Ocean, etc. are another option. With these services, you are effectively ‘renting’ computing, storage, and processing resources on an as-needed basis. These services trade hardware control for elasticity.
New resources can be requested and existing resources upgraded in a matter of minutes, often with no noticeable downtime to users. For applications where traffic may be unpredictable or “spurty” (e.g. selling tickets to a venue, where traffic may be very high when tickets first go on-sale but be much lower the rest of the time), resources can be added or removed dynamically depending on current or expected demand.
Pros
Easy to scale up or down.
Managed services for databases, storage, and networking.
Can support high availability across regions and zones.
Cons
Dollar-for-dollar, cloud will almost always be more expensive than owning or even renting your own hardware.
Added complexity and a steeper learning curve for management.
Phase 3: Splitting Responsibilities
Whether an app is being hosted “on-prem” or via the “cloud”, the next way to optimize is to divide workloads into specific resources. Rather than having one virtual machine that handles everything, you set up multiple machines each with a specific purpose. For example, you might structure it so that:
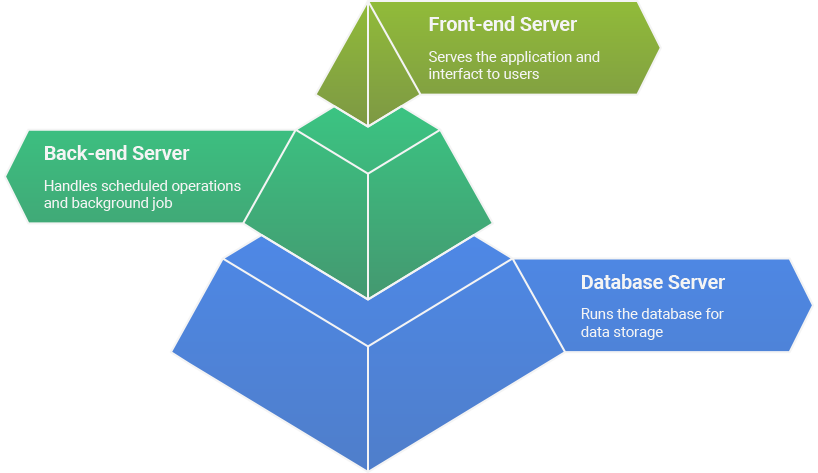
Front-end Server
One resource serves the front end application to users.
Back-end Servers
Others serve the back-end operations and ‘background jobs’ (e.g. sending emails, generating reports, executing AI jobs, etc.)
Database
This resource runs the database (and only the database).
Separating these tasks across different resources allows more fine-grained scaling decisions to be made depending on application demands. If, for example, your front-end requires very few resources but the database is the bottleneck, you can increase the size of the database without spending money on also increasing the size of the front-end server.
However, at this stage you still only have one instance or copy of each of these resources.
Phase 4: Horizontal Scaling
Here’s where true scalability begins.
Instead of running one very large application server, you instead run multiple (often smaller and less expensive) app servers (“nodes”), and place a gateway or load balancer in front to distribute requests evenly. Users connect to the gateway, and the gateway then connects to one of several app server nodes to handle the request.
Pros
You can add or remove nodes and capacity as needed, paying only for what you require at the moment (elasticity).
Improved throughput for parallel workloads.
Cons
Increased complexity for provisioning and managing resources.
Must be carefully set up to avoid runaway costs.
Phase 5: Using Off-Server Object Storage
When you have multiple servers, storing files locally on that server becomes a liability.
Consider what happens if User 1 uploads an image to their social media timeline while connected to Server A. The file is stored on Server A. If User 2 then tries to view the image while talking with Server B, the link will be broken, because Server B does not have a copy of the image that was uploaded to Server A.
The solution? Object storage.
Systems like AWS S3, Azure Blob, or DigitalOcean Spaces let every app instance read and write to the same shared storage. You can think of it like a Dropbox or OneDrive account, but just for your app to use behind the scenes. This way, it does not matter how many app servers you are running – they all have access to the same stored files.
This makes your app stateless, which is essential for:
- Auto-scaling (adding or removing resources to meet traffic demands)
- Rolling deployments (updating servers with new versions of your app)
- High availability (redundancy in case one app server fails for some reason)
Once stateless, you can scale confidently — your app nodes are now interchangeable.
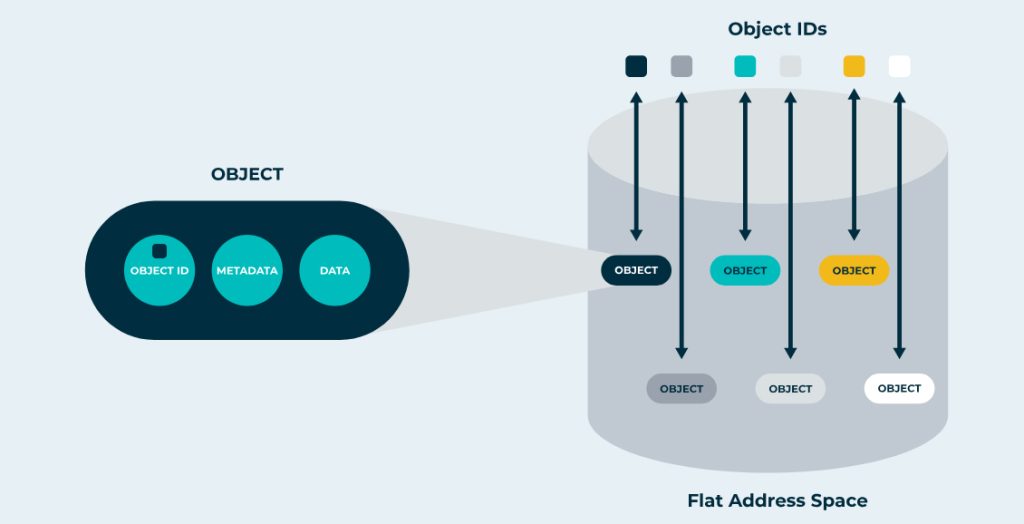
Source: Object Storage Solutions
Phase 6: Caching
A cache stores (in very fast memory) the results of an operation that otherwise might be rather slow to complete. By keeping the information in memory, the app can access that much more quickly than if it needs to ask a database or load a file from disk. For example, if on every page of your site you need to load a list of office locations to display at the bottom of the page, caching that list (which won’t change often) will avoid having to access the database to retrieve the information. Caching is often the single biggest performance improvement you can make. A well-placed cache can reduce database load by up to 90%.
Caching is often the single biggest performance improvement you can make. A well-placed cache can reduce database load by up to 90%.
However, caching can become complicated, because the app must also take care to purge or delete any items from the cache that are now out of date. If, for example, an administrator deletes a now-closed office location, you would not want that to continue to show up in the footer of the web pages. Mechanisms for identifying and refreshing ‘stale’ information in the cache must be considered.
Phase 7: CDN - Speed Meets Reach
Even the fastest servers can’t beat the laws of physics. If your users are global (in Canada, the United States, Asia, and Australia, for example), then latency (the time it takes for a request to travel from your user to your app and back) becomes your next enemy.
Enter the Content Delivery Network (CDN).
A CDN caches static assets that do not change very often (such as photographs, style sheets, and JavaScript code) at edge locations around the world, serving them from the data center closest to your users.
On platforms like Cloudflare, Fastly, or CloudFront, this can be as simple as toggling a setting.
Adding a CDN is often the biggest bang-for-buck optimization a growing app can make if it depends significantly on publicly-available static assets.
Pros
Lower origin server load
Built-in redundancy
Phase 8: Database Scaling and Replication
Your database eventually becomes the bottleneck. All your writes, reads, and reporting queries flow through the same server — until it starts gasping for air.
Introduce Read Replicas
Most databases (PostgreSQL, MySQL, MS SQL etc.) support replication, where one database is considered the ‘primary’ node, and one or more additional ‘replicas’ are also available to respond to queries. If your app depends more on reading from the database than writing to the database – and most will! – then this can help spread the load.
Any writes to the database (inserting, updating, or deleting records) are made to the ‘primary’ node, which then copies itself to the other read replicas. ‘Read’ queries can be spread across all of the replicas to distribute the load.
The result? Huge read capacity, less contention, and added redundancy. There is a small delay between when a write is made and when that is reflected in the other read replicas, but this is typically an acceptable trade-off.
Think About Partitioning
If you’re managing massive datasets, you may later split data by user group, date, region, or ID range — known as sharding. For example, in an accounting system, it may be reasonable or acceptable to store each year’s transactions in its own separate database, thereby reducing the amount of data that must be analyzed for reporting purposes in a single year. This is an advanced and complex topic, but sometimes becomes necessary for very large-scale systems.
For most teams, however, read replicas + caching already deliver massive scalability.
Phase 9: Multi-Zone and Multi-Region Deployments
As reliability, redundancy, and large-scale usage becomes a business goal, the next evolution is redundancy.
In multi-zone redundancy, you deploy your app to multiple “availability zones” within a single region. This might amount to having two copies of the app running, one in each of two data centers located in different parts of a city. If one data center fails, the other stays online. Most cloud providers support this automatically.
In multi-region redundancy, for mission-critical systems or global apps, you might deploy full stacks (app, DB, cache, storage) in multiple regions. Traffic is routed to the most appropriate instance based on geography or health checks.
Most mid-sized apps stop comfortably at multi-zone redundancy — the right balance of simplicity and reliability.
Pros
Faster response times for global users.
Cons
Complex failover orchestration. Determining where traffic should be routed, what should happen if a particular copy of the app becomes unavailable, and how that copy of the app should get back up to speed once it is back online, can be very complicated procedures.
Higher operational costs. Every additional zone or region multiplies the operating cost.
Every App’s Journey Is Unique
Here’s the truth: There’s no single “right” path to scaling.
Some apps might jump straight to CDNs and caching without ever needing worker nodes. Others (like video platforms or analytics tools) might focus heavily on background workers and object storage before worrying about load balancers.
Scaling is contextual. It’s less about following a recipe, and more about listening to the system:
- Where are the slowdowns?
- What’s the real source of pain?
- What’s the simplest way to fix it sustainably?
Measure, observe, adjust — then evolve intentionally. Do not forget to re-evaluate past decisions to determine whether those are still “correct” in light of the evolving context, too!
Final Thoughts
Scaling an app isn’t just an engineering milestone. It’s a journey of maturity for your product, your team, and your infrastructure.
Start simple. Monitor constantly. Scale what matters, when it matters. To be sure, when planning a system, you should be alert to what might be necessary in the future. For example, using object storage for uploaded files from the get-go may be a sensible architectural decision to avoid having to re-work that service in the future. But, you don’t necessarily need Kubernetes clusters or multi-region database replicas to be “real.” Even the biggest systems in the world started with a single server, and grew one decision at a time.
So wherever you are in your scaling journey, remember: The goal isn’t more infrastructure. It’s better user experiences. Optimize for your users.
Want to learn more?
Vertical Motion is a trusted Canadian software development and entrepreneur assistance company that has supported the global efforts of startups, non-profits, B2B, and B2C businesses since 2006. With headquarters in Calgary and Kelowna, and team members coast to coast, Vertical Motion is recognized as an award-winning leader in the technology industry. Our team of executive advisors, project managers, software developers, business analysts, marketing specialists, and graphic designers have extensive experience in several industries including — Energy, Finance, Blockchain, Real Estate, Health Care, Clean Technology, Clothing & Apparel, Sports & Recreation, Software as a Service (SaaS), and Augmented & Virtual Reality (AR/VR).
Come chat with us and let us take you “From Idea to Execution and Beyond!” 🚀