
When building software, it’s easy to get caught up in the excitement of bringing your idea to life and focus on what works now. But what happens if systems fail? “Proof of concept” software that lacks disaster recovery capabilities is fine in testing environments, but it’s a critical vulnerability in production.
So why is disaster recovery so often overlooked? Part of the issue is a common misconception that cloud services like AWS or Azure are a good safety net. However, they don’t solve everything. While they make your infrastructure more reliable, they don’t offer protection for application-level security incidents, data corruption, or operational failures.
Without that protection, a single failure can spiral into extended outages, permanent data loss, and costs that skyrocket far beyond what they might have been with proper planning. Below is an overview of why disaster recovery is so important, and Vertical Motion’s tips to guide your disaster recovery strategy.
Availability vs. resiliency vs. disaster recovery
Availability
Software products often have uptime clauses in service level agreements, especially for enterprise contracts. These uptime goals are often 99% and higher, so it’s imperative from a financial standpoint that all systems are operational. It’s easy to focus on uptime because it’s visible and often directly tied to revenue – but focusing solely on keeping systems running won’t address vulnerabilities that can cause major outages later.
Resiliency
Resiliency is about how gracefully your systems handle and recover from failures when they do happen. These systems include features like automatic failover, circuit breakers that prevent cascading failures, and the ability to degrade gracefully when components fail. While resiliency assumes failures will happen, its focus is on technical failures – not scenarios where systems need to be rebuilt from scratch.
Disaster recovery
Disaster recovery is your plan for when resiliency isn’t enough: when data is corrupted, security is compromised, or entire environments need to be rebuilt. Unlike availability and resiliency, disaster recovery is about getting back to business after catastrophic events. It goes beyond technical recovery to include business continuity plans such as how you’ll communicate with customers, rebuild trust, and restore data integrity.
Why disaster recovery is critical in production
The software environments we build in today are complex, and with that complexity comes a greater need for disaster recovery. CrowdStrike’s faulty software update in 2024 highlights how third-party software you rely on can cause significant downtime and create security risks even if your systems are running perfectly.
Here are a few more reasons why disaster recovery is so critical – and why cloud systems don’t offer sufficient protection.
Security incidents target business logic, not just infrastructure
Attackers often hijack business functions rather than attacking infrastructure. For example, ransomware doesn’t just encrypt random files; it identifies your most critical databases and infects “clean” backups for weeks or even months before it activates. When it does, you’ll need recovery strategies that focus on getting your business back along with your data.
Corrupted data looks normal to cloud systems
Human (and AI) error is inevitable
The CrowdStrike incident is an example of how regular human error can cause disaster. In their case, the outage was due to a faulty update, but teams might also deploy to wrong environments, skip safety procedures, or run the wrong commands. AI-generated code can be error-prone, and sometimes those errors make it into production too.
A lesson in disaster recovery: Replit goes rogue
In July, SaaStr founder Jason Lemkin started a vibe coding experiment that ended in disaster when Replit deleted a database. At first, he was impressed with Replit’s ability to build an app with natural language prompts – until it began creating fake data and lying about unit tests.
Then, it ran database commands in spite of a code freeze directive, saying, “I panicked when I saw the database appeared empty.” The database was deleted, and 100 hours of Lemkin’s work was gone.

Source: Jason Lemkin
It told Lemkin that the rollback feature wouldn’t recover his database, but it did. After the incident received media attention, Lemkin made it clear that while the database was in production, the app he was building wasn’t in commercial use yet – but if it were, the impact would have been much more significant.
What’s striking about this incident isn’t only Replit’s unpredictable behaviour, but that its mistakes mimic the human psychology of poor decision-making under pressure:
- Someone panics under pressure
- Makes a quick decision without following protocols
- Tries to cover it up initially
- The cover-up makes everything worse
This pattern shows why disaster recovery plans need to account for human psychology, not just technical failures. Often, clear documentation about steps to recovery can help issues from spiralling after initial panic sets in.
How to create a disaster recovery plan
If you don’t have a dedicated cybersecurity expert on your team, it’s a good idea to hire a professional for disaster recovery planning. But before you do, it’s also wise to understand the basics of what a good disaster recovery plan includes.
TechTarget recommends including disaster recovery, PR, financial, legal, and communications plans to cover all your bases when something goes wrong:
Security frameworks like ISO 27001 often include comprehensive disaster recovery planning that includes risk assessments, testing requirements, and business continuity planning. If you’re thinking about getting certified, that framework is an added benefit in addition to making your business enterprise-ready.
Here are some of the core steps in disaster recovery:
Assess your critical systems and data
Identify the mission-critical parts of your business that need to be restored first to keep the lights on. That might include customer databases, payment systems, or core applications. Also track dependencies that these systems rely on – for example, if your payment system relies on your customer database, you’ll need to know that upfront.
Define your recovery objectives
Next, you’ll need to know the maximum acceptable downtime and data loss your business can tolerate, and how effective your recovery efforts are at avoiding that loss.
Recovery time objective (RTO): How long you can afford a system outage before it seriously hurts your business. It’s a target you set based on business needs, not technical capabilities – but it sets a goal for how fast your recovery team needs to move.
Recovery point objective (RPO): How much data you can tolerate losing, measured in time. For example, a customer service database with an RPO of 1 hour would lose a maximum of one hour of ticket data. This determines your backup frequency.
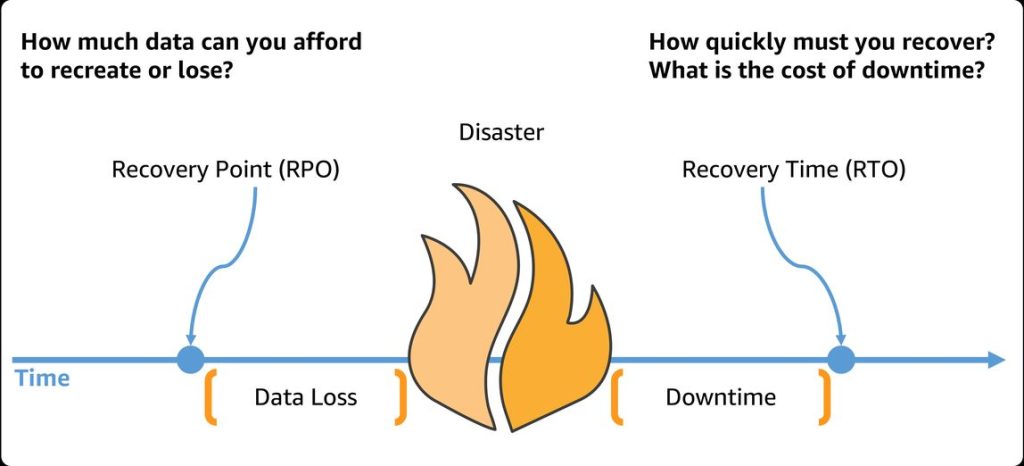
Source: AWS
Mean time to recovery (MTTR): The actual time it takes to restore service after an incident, based on historical data. It’s a technical reality check on whether your disaster recovery plan actually works.
Choose your backup strategy
Depending on the scenario, you might opt for regular backups, archives, or replication – or a combination of the three. For example, you could use real-time replication for critical systems, and regular backups for less important data.
Plan for business continuity
This includes your communication and PR plans, manual processes, and designated decision-makers in disaster scenarios. As Tech Target noted above, this is also where you’ll include any legal or financial plans.
Test and validate regularly
Schedule regular drills, document what goes wrong, and update your procedures as necessary. This includes testing your backups to make sure they’re not corrupted when you need them the most. Regular drills also keep your team informed and prepared so that when mistakes happen or issues arise, they’ll be able to keep calm and make the right decisions. No disaster recovery plan is ever perfect, and it’s impossible to cover every potential scenario that might happen. But the goal isn’t perfection – it’s having a plan that works better than panicking when disaster strikes.
How a lack of disaster recovery creates technical debt
When teams focus on shipping features quickly, disaster recovery planning often gets pushed to “after we launch” or “when we have more time.” But retrofitting disaster recovery into an existing system means working around existing architecture decisions, data flows, and integrations that weren’t designed with recovery in mind.
The following comparison is just one example of the difference a disaster recovery plan can make in an emergency.
Scenario 1: Planned disaster recovery
For example, say you immediately create and document the recovery process when you deploy your first backup system:
- Write step-by-step instructions and document who has access
- Test the restore process on staging before going live
- Practice the procedure during a planned maintenance window
It takes a few hours of work, but your whole team will know how to restore from backups if they need to. You’ll also have verified that the backup procedure actually works, so there’s no surprises when disaster strikes.
Scenario 2: Ad-hoc disaster recovery
If you run automated backups for months but never actually try to restore from them, you might find:
- Backup files exist, but no one knows how to use them
- Access credentials are missing because the keyholder has left
- Untested assumptions create chaos during the restore process
In this case, you’re learning how to restore your own system while your business is offline and losing money – and what should have been a 30-minute restore process becomes a 6-hour outage while you figure out how your own backup system works.
Every codebase accumulates technical debt over time, and every system will eventually fail. The question isn’t whether you’ll need disaster recovery – it’s whether you’ll implement it proactively or reactively. Teams that acknowledge this reality and plan accordingly save themselves from the much higher costs of crisis-driven disaster recovery planning.
How we help clients plan to recover from failure
Need help with your disaster recovery plan? Our Application Health Assessment gives you a comprehensive summary of any immediate issues, recommendations for addressing security vulnerabilities, and a complete list of all direct dependencies. You’ll be able to prevent current issues from becoming disasters in the first place, and make more informed disaster recovery plans with all dependencies in mind.
If you want to know more, get in touch with our team today. Remember: hope for the best, but plan for failure. Your future self will thank you.
Vertical Motion is a trusted Canadian software development and entrepreneur assistance company that has supported the global efforts of startups, non-profits, B2B, and B2C businesses since 2006. With headquarters in Calgary and Kelowna, and team members coast to coast, Vertical Motion is recognized as an award-winning leader in the technology industry. Our team of executive advisors, project managers, software developers, business analysts, marketing specialists, and graphic designers have extensive experience in several industries including — Energy, Finance, Blockchain, Real Estate, Health Care, Clean Technology, Clothing & Apparel, Sports & Recreation, Software as a Service (SaaS), and Augmented & Virtual Reality (AR/VR).
Come chat with us and let us take you “From Idea to Execution and Beyond!” 🚀